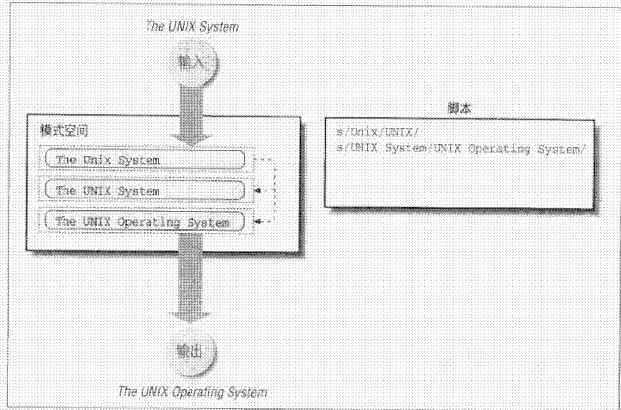
高级命令分为3个组:
- 处理多行模式空间(N,D,P)。
- 采用保持空间来保存模式空间的内容,并使它用于后续命令(H,h,G,g,x)。
- 编写使用分支和条件指令的脚本来更改控制流(:,b,T/t)。
多行模式空间
awk,sed,grep的模式匹配是面向行的,在单个输入行上匹配一个模式。但是其他如在一行的结尾处开始到下一行的开始处结束的短语,则只有在多行上重复时才有意义。
sed能察看模式空间的多个行,允许匹配模式扩展到多行上.
这里的3个多行命令(N,D,P)对应于之前的小写字母的基本命令(n,d,p)。命令解释
D/d: d删除模式空间的内容,D只是删除模式空间的第一行内容。
P/p: p打印当前模式空间内容,追加到默认输出之后,P(大写)打印当前模式空间开端至\n的内容,并追加到默认输出之前。
N/n: Next(N)通过读取新的输入行,并将它添加到模式空间的现有内容之后来创建多行模式空间。模式空间最初的内容和新的输入行之间用换行符分隔。多行模式空间中,“^”匹配空间中的第一个字条,而不是换行符后面的字符,“$”只匹配模式空间中最后的换行符,不匹配任何嵌入的。next(n)输出模式空间的内容,然后读取新的输入行。实例
n
1
2
3
4
5
6
7
8
9
10cat aaa
This is 1
This is 2
This is 3
This is 4
This is 5
sed -n 'n;p' aaa //-n表示隐藏默认输出内容
This is 2
This is 4
注 释:读取This is 1,执行n命令,此时模式空间为This is 2,执行p,打印模式空间内容This is 2,之后读取 This is 3,执行n命令,此时模式空间为This is 4,执行p,打印模式空间内容This is 4,之后读取This is 5,执行n 命令,因为没有了,所以退出,并放弃p命令。
N
1 | sed -n '$!N;P' aaa |
注释中1代表This is 1 2代表This is 2 以此类推
注释:读取1,$!条件满足(不是尾行),执行N命令,得出1\n2,执行P,打印得1,读取3,$!条件满足(不是尾行),执行N命令,得出3\n4,执行P,打印得3,读取5,$!条件不满足,跳过N,执行P,打印得5.
$!N: 排除了对最后一行($)执行Next命令。http://blog.chinaunix.net/uid-10540984-id-1759548.html1
2
3
4
5cat text
Owner and Operator
Guide
sed '/Operator$/ {N;s/Owner and Operator\nGuide/Installtion Guide/ }' text
Installtion Guide
关于更详细的关于sed参数n和N,见ww.cbcb.umd.edu/software/PBcR/MHAP/asm/
d
1 | sed 'n;d' aaa |
注释:读取1,执行n,得出2,执行d,删除2,得空,以此类推,读取3,执行n,得出4,执行d,删除4,得空,但是读取5时,因为n无法执行,所以d不执行。因无-n参数,故输出1\n3\n5.
D
1 | sed 'N;D' aaa |
注释:读取1,执行N,得出1\n2,执行D,得出2,执行N,得出2\n3,执行D,得出3,依此类推,得出5,执行N,条件失败退出,因无-n参数,故输出5.
输入/输出循环
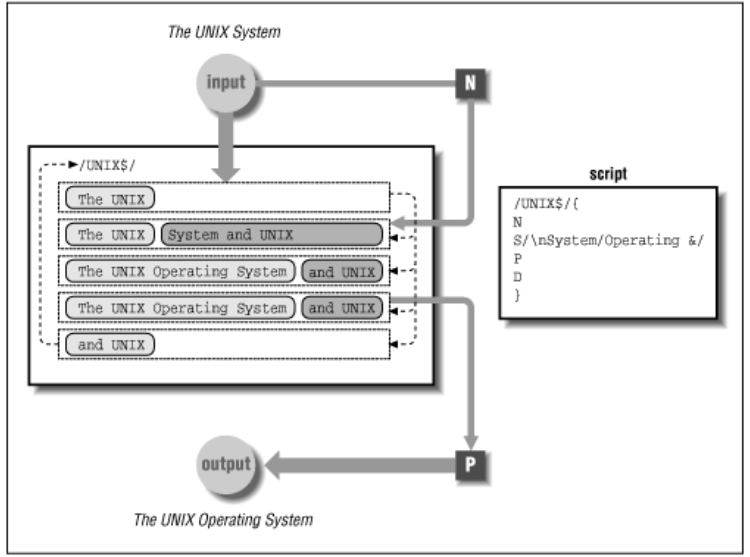
P(大写)经常出现在N之后D之前,通过N-P-D可建立一个输入/输出循环,用来维护两行的模式空间,但是一次只输出一行。这个循环的目的是只输出模式空间的第一行,然后返回到脚本的顶端将所有的命令应用于模式空间的第二行。
案例分析:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61$ cat text.txt
I want to see @f1(what will happen) if we put the
font change commands @f1(on a set of lines). If I understand
things (correctly), the @f1(third) line causes problems.(No?).
Is this really the case, or is it (maybe) just something else?
Let's test having two on a line @f1(here) and @f1(there) as
well as one that begins on one line and ends @f1(somewhere
on another line). What if @f1(it is here) on the line?
Another @f1(one).
$ #将@f1(anything)替换为\fB anything \fR
$ sed 's/@f1(\(.*\))/\\fB\1\\fR/g' #匹配@f1(.*) 并用“\(” 和 “\)” 保存括号中任意内容,在替换部分,保存的匹配部分用“\1” 回调。
$ sed -f sed.len test
I want to see \fBwhat will happen\fR if we put the
font change commands \fBon a set of lines\fR. If I understand
things (correctly), the \fBthird) line causes problems. (No?\fR.
Is this really the case, or is it (maybe) just something else?
Let's test having two on a line \fBhere) and @f1(there\fR as
well as one that begins on one line and ends @f1(somewhere
on another line). What if \fBit is here\fR on the line?
Another \fBone\fR.
$ #替换命令在第三行和第二段第一行失效,正则表达式贪婪匹配总是进行可能最长的匹配,“.*”匹配从"@f1(" 到这一行最后一个右圆括号中所有字符。
$ sed 's/@f1(\([^)]*\))/\\fB\1\\fR/g' #除“)”以外的零次或多次出现的任意字符
I want to see \fBwhat will happen\fR if we put the
font change commands \fBon a set of lines\fR. If I understand
things (correctly), the \fBthird\fR line causes problems.(No?).
Is this really the case, or is it (maybe) just something else?
Let's test having two on a line \fBhere\fR and \fBthere\fR as
well as one that begins on one line and ends @f1(somewhere
on another line). What if \fBit is here\fR on the line?
Another \fBone\fR.
$ #可以看到对于跨越两行的替换仍然没有完成。这时多行模式空间变可发挥其神奇功效了,如果匹配“@f1(” 并且没有找到右圆括号的话,那么就需要将另一行读入(N)缓冲区并试着生成与第一种情况相同的匹配。
$ cat sednew
s/@f1(\([^)]*\))/\\fB\1\\fR/g
/@f1(.*/ {
N
s/@f1(.*\n[^)]*\))/\\fB\1\\fR/g
}
$ #/@f1(.*/地址将过程限制在匹配/@f1(.*/的行上,并对其执行{}中的命令。
$ sed -f sednew test
I want to see \fBwhat will happen\fR if we put the
font change commands \fBon a set of lines\fR. If I understand
things (correctly), the \fBthird\fR line causes problems.(No?).
Is this really the case, or is it (maybe) just something else?
Let's test having two on a line \fBhere\fR and \fBthere\fR as
well as one that begins on one line and ends \fBsomewhere
on another line\fR. What if @f1(it is here) on the line?
Another \fBone\fR.
$ #可以看出倒数第二个替换不成功,why? 模式匹配/@f1(.*/找到@f1(somewhere\n后执行N输入第二行,此时模式空间为“well as one that begins on one line and ends @f1(somewhere\non another line). What if @f1(it is here) on the line?“,进行第二行脚本替换命令"s/@f1(.*\n[^)]*\))/\\fB\1\\fR/g",模式空间变为"well as one that begins on one line and ends \fBsomewhere\non another line\fR. What if @f1(it is here) on the line?"并一起输出,然后sed再次输入的是最后一行“Another @f1(one)”来从头执行脚本;我们发现这个替换脚本似乎是”忘记“了@f1(it is here)的存在,成功跳过它完成匹配。而这原因就是sed默认是输出模式空间的整个内容,所以@f1(it is here)没有机会让脚本程序重头对其执行,也就没能通过脚本第一行替换完成任务。
$ #如果我们在多行模式空间中完成跨越两行的匹配替换后只是输出第一行(P),然后将其删除(D),这样剩下的“What if @f1(it is here) on the line?”部分成为模式空间的第一行,并将控制转移到脚本的顶端,这时检查是否在该行上还有其他的“@f1(”,这得到机会让脚本从上至下的所有命令应用到它完成替换。
$ cat sednew2
s/@f1(\([^)]*\))/\\fB\1\\fR/g
/@f1(.*/ {
N
s/@f1(\(.*\n[^)]*\))/\\fB\1\\fR/g
P
D
}
大于2行模式空间
我们发现Next(N)命令只能的在读入第一行的基础上再次读入下一行,即模式空间中同时存在2行,如果想要匹配3行或更多怎么办?
这时就该高级的流控制命令起作用了。
其中用于控制执行脚本的哪一部分以及何时执行的命令为分支(b)和测试(T/t),他们将脚本中的控制转移到包含特殊标签的行,如果没有标签被指定,则转移到脚本结尾处。分支用于无条件转移,测试用于有条件转移。
标签是任意不多于7个字符的序列,标签本身占据一行并以冒号开始:1
:mylabel
注:冒号和标签间不允许有空格,行尾处的空格是标签的一部分。当在分支和测试命令中指定标签时,在命令和标签间允许有空格:1
b mylabel
所以对于大于2行的模式空间匹配可以通过一下实现:1
2
3
4
5
6
7
8
9
10
11
12
13
14:begin
/@f1(\([^)]*\))/{
s//\\fB\1\\fR/g
b begin
}
/@f1(.*/{
N
s/@f1(\([^)]*\n[^)]*\))/\\fB\1\\fR/g
t again
b begin
}
:again
P
D
保持空间
模式空间是容纳当前输入的缓冲区。还有一个保持空间(hold space)的顶留(set-aside)缓冲区,模式空间和保持空间内容可实现互换。保持空间用于临时存储,单独的命令不能寻址保持空间或更改他的内容。
保持空间最常用的当改变模式空间中的原始内容时,用于保留当前输入行的副本。
y
y命令的作用在于字符转换
将aaa文件内容大写1
2
3
4
5
6
7
8
9sed 'y/his/HIS/' aaa
THIS IS 1
THIS IS 2
THIS IS 3
THIS IS 4
THIS IS 5
#或者echo "axxbxxcxx" | sed 'y/abc/123/'
1xx2xx3xx
#不连续字符串的替换
h命令,H命令,g命令,G命令
h命令是将当前模式空间中内容覆盖至保持空间,H命令是将当前模式空间中的内容追加至保持空间
g命令是将当前保持空间中内容覆盖至模式空间,G命令是将当前保持空间中的内容追加至模式空间1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22cat ddd
This is a and a is 1
This is b and b is 2
This is c and c is 3
This is d and d is 4
This is e and e is 5
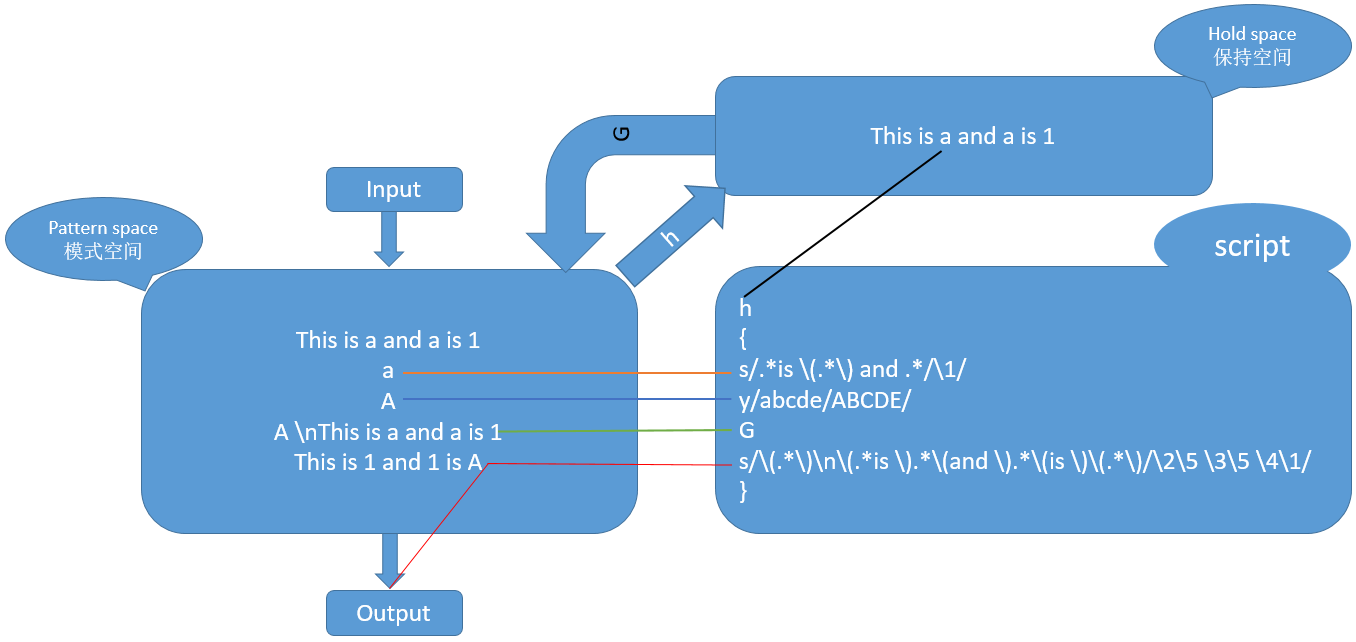
#将ddd文件中数字和字母互换,并将字母大写
cat ddd.sed
h
{
s/.*is \(.*\) and .*/\1/
y/abcde/ABCDE/
G
s/\(.*\)\n\(.*is \).*\(and \).*\(is \)\(.*\)/\2\5 \3\5 \4\1/
}
sed -f ddd.sed ddd
This is 1 and 1 is A
This is 2 and 2 is B
This is 3 and 3 is C
This is 4 and 4 is D
This is 5 and 5 is E
x
x命令是将当前保持空间和模式空间内容互换.
