awk中有两种类型的系统变量。第一种类型定义的变量默认值可以改变,如字段和记录分隔符;第二种类型定义的变量的值可用于报告或数据处理中,如字段数量或记录数量。
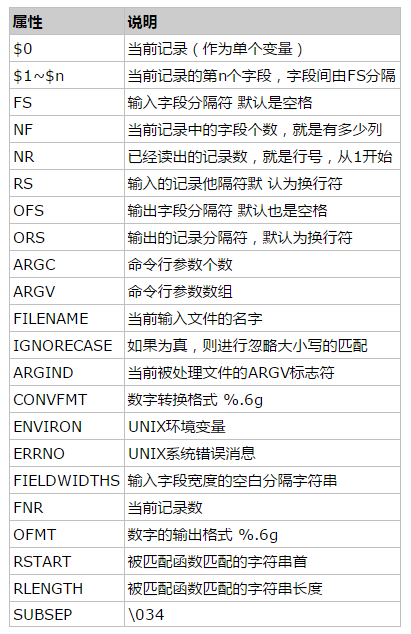
内置变量表

实例
处理多行记录
1 | $ cat text.txt |
注:6个字段,记录之间用空行分隔。
为了处理这种包括多行数据的记录,可以将字段分隔符定义为换行符,记录分隔符定义为空字符串,代表一个空行。1
BEGIN{FS="\n";RS=""}
所以可以用下面脚本打印第一个和最后一个字段:1
2$ awk 'BEGIN{ FS = "\n"; RS = "" } {print $1, $NF}' text.txt
John Robinson 696-0987
输出数据格式设置:(OFMT使用)
1 | $ awk 'BEGIN{OFMT="%.3f";print 2/3,123.11111111;}' /etc/passwd |
按宽度指定分隔符(FIELDWIDTHS使用)
1 | $ echo 20100117054932 | awk 'BEGIN{FIELDWIDTHS="4 2 2 2 2 3"}{print $1"-"$2"-"$3,$4":"$5":"$6}' |
内置函数
awk内置函数,主要分以下3种类似:算数函数、字符串函数、其它一般函数、时间函数
字符串函数

split
awk的内建函数split允许你把一个字符串分隔为单词并存储在数组中。你可以自己定义域分隔符或者使用现在FS(域分隔符)的值。
格式:
split (string, array, field separator)
split (string, array) —>如果第三个参数没有提供,awk就默认使用当前FS值。
split有3个参数,第一个传要切分的字符串,第二个放切分完后输出的数组,第三个定义分隔符;1
2
3
4
5$ awk 'BEGIN{info = "this is a test";slen=split(info,ta," ");for (i=1;i<=slen;i++) {print i,ta[i];}}'
1 this
2 is
3 a
4 test
参考:
http://www.cnblogs.com/chengmo/archive/2010/10/06/1844818.html
