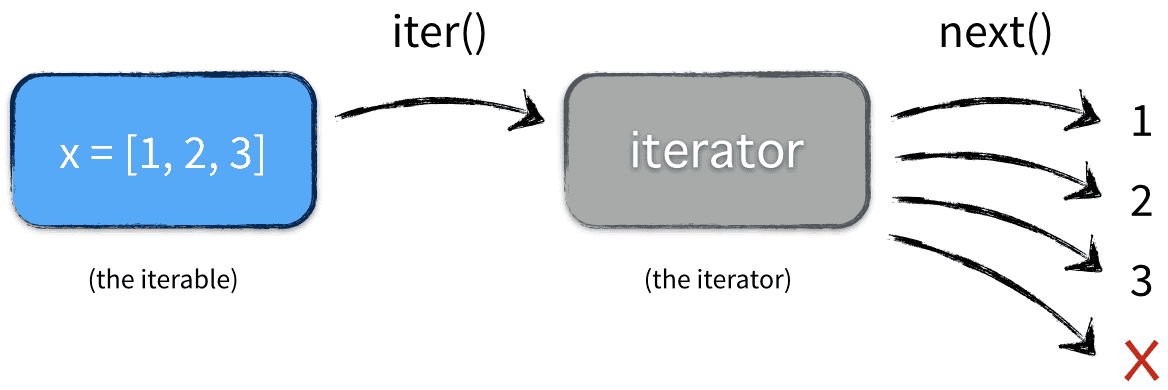
直接概念
可迭代对象(Iterable): 可以直接作用于for循环的对象;
迭代器(Iterator): 可以被next()函数调用并不断返回下一个值的对象。
所有的Iterable均可通过内置函数iter()来转变为Iterator。
迭代器
关于迭代器我们需要注意以下几点:
1. 迭代器不可重复利用,迭代完就变成空了,再次调用会引发StopIteration异常;
可通过copy包中的deepcopy复制迭代器从而可循环使用。
2. 迭代器是访问集合内元素的一种方式。迭代器对象从集合的第一个元素开始访问,直到所有的元素都被访问一遍后结束;
3. 迭代器不能回退,只能往前进行迭代;
4. 对于原生支持随机访问的数据结构(如tuple、list),迭代器和经典for循环的索引访问相比并无优势,反而丢失了索引值(可以使用内建函数enumerate()找回这个索引值)。但对于无法随机访问的数据结构(比如set)而言,迭代器是唯一的访问元素的方式;enumerate()能在iter函数的结果前加上索引,以元组返回:1
2
3
4
5
6
7lst = [5,6,7]
for idx, ele in enumerate(lst):
print idx, ele
0 5
1 6
2 7
5. 迭代器的另一个优点就是它不要求你事先准备好整个迭代过程中所有的元素。迭代器仅仅在迭代至某个元素时才计算该元素,而在这之前或之后,元素可以不存在或者被销毁。这个特点使得它特别适合用于遍历一些巨大的或是无限的集合,比如几个G的文件,或是斐波那契数列等等。这个特点被称为延迟计算或惰性求值(Lazy evaluation);
6. 迭代器更大的功劳是提供了一个统一的访问集合的接口。只要是实现了iter()方法的对象,就可以使用迭代器进行访问。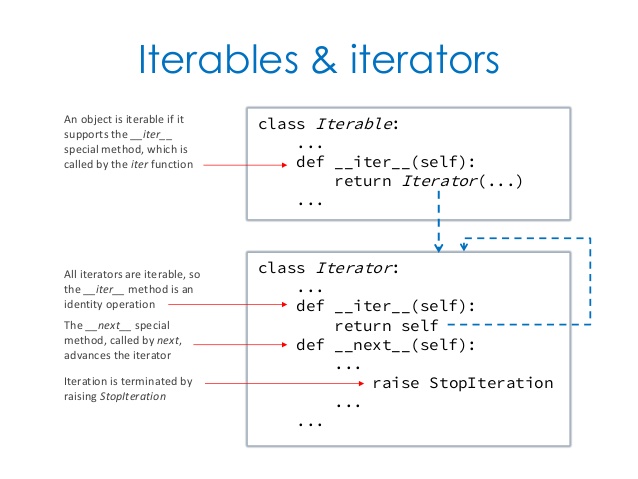
迭代器操作
使用内建函数iter(iterable)获取迭代器对象,next(iterator)访问下一个元素;
常用的几个内建数据结构tuple、list、set、dict都支持迭代器,字符串也可以使用迭代操作。
itertools模块
Python的内建模块itertools提供了非常有用的用于操作迭代对象的函数。
“无限”迭代器
无限序列只有在for迭代时才会无限地迭代下去,如果只是创建了一个迭代对象,它不会事先把无限个元素生成出来;
count
count()会创建一个无限的迭代器:1
2
3
4
5
6
7
8i = 0
for item in itertools.count(100):
if i>10:
break
print item,
i = i+1
100 101 102 103 104 105 106 107 108 109 110
cycle
cycle()会把传入的一个序列无限重复下去:1
2
3
4
5
6
7
8
9
10
11
12import itertools
cs = itertools.cycle('ABC') # 注意字符串也是序列的一种
for c in cs:
print c
...
'A'
'B'
'C'
'A'
'B'
'C'
...
repeat
repeat(elem [,n])repeat负责把一个元素无限重复下去,不过如果提供第二个参数就可以限定重复次数:
附: print后面逗号,作用1
2
3
4
5
6
7
8
9
10
11
12
13
14import itertools
listone = ['a','b','c']
for item in itertools.repeat(listone,3):
print item,
['a', 'b', 'c'] ['a', 'b', 'c'] ['a', 'b', 'c']
import itertools
listone = ['a','b','c']
for item in itertools.repeat(listone,3):
print item
['a', 'b', 'c']
['a', 'b', 'c']
['a', 'b', 'c']
以上无限序列虽然可以无限迭代下去,但是通常我们会通过takewhile()等函数根据条件判断来截取出一个有限的序列:1
2
3
4
5
6natuals = itertools.count(1)
ns = itertools.takewhile(lambda x: x <= 10, natuals)
for n in ns:
print n
...
打印出1到10
迭代器操作函数
chain
chain()可以把一组迭代对象串联起来,形成一个更大的迭代器:1
2
3
4
5
6
7
8
9
10
11
12import itertools
listone = ['a','b','c']
listtwo = ['11','22','abc']
for item in itertools.chain(listone,listtwo):
print item
a
b
c
11
22
abc
ifilter
ifilter(fun,iterator)返回一个可以让fun返回True的迭代器:1
2
3
4
5
6
7
8
9import itertools
def funLargeFive(x):
if x > 5:
return True
for item in itertools.ifilter(funLargeFive,range(-10,10)):
print item,
6 7 8 9
imap
imap(fun,iterator)返回一个迭代器,对iterator中的每个项目调用fun:1
2
3
4
5
6
7
8
9
10
11import itertools
listthree = [1,2,3]
def funAddFive(x):
return x + 5
for item in itertools.imap(funAddFive,listthree):
print item,
print type(item)
...
6 <type 'int'>
7 <type 'int'>
8 <type 'int'>
imap()和map()的区别在于,imap()可以作用于无穷序列,并且,如果两个序列的长度不一致,以短的那个为准。
和直接map的区别如下:1
2
3
4
5
6
7
8> listthree = [1,2,3]
> def funAddFive(x):
... return x + 5
...
> map(funAddFive,listthree)
[6, 7, 8]
> type(map(funAddFive,listthree))
list
imap()返回一个迭代对象,而map()返回list,并且当你调用map()时,结果已经计算完毕,而当你调用imap()时,并没有进行任何计算,必须用for循环对其进行迭代,才会在每次循环过程中计算出下一个元素,从而实现了“惰性计算”,也就是在需要获得结果的时候才计算。
islice
itertools.islice(iterable, stop)itertools.islice(iterable, start, stop[, step])
返回迭代器,将seq,从start开始,到stop结束,以step步长切割:
If start is None, then iteration starts at zero. If step is None, then the step defaults to one.1
2
3
4
5
6
7
8import itertools
listone = ['a','b','c']
listtwo = ['11','22','abc']
listthree = listone + listtwo
for item in itertools.islice(listthree,3,5):
print item,
11 22
izip
izip(*iterator)返回迭代器,结果是元组,元组来自*iterator的组合1
2
3
4
5
6
7
8
9
10
11import itertools
listone = ['a','b','c']
listtwo = ['11','22','abc']
listthree = listone + listtwo
for item in itertools.izip(listone,listtwo):
print item,
print type(item)
('a', '11') <type 'tuple'>
('b', '22') <type 'tuple'>
('c', 'abc') <type 'tuple'>
groupby()
groupby()把迭代器中相邻的重复元素挑出来放在一起:1
2
3
4
5
6
7for key, group in itertools.groupby('AAABBBCCAAA'):
print key, list(group) # 为什么这里要用list()函数呢?
...
A ['A', 'A', 'A']
B ['B', 'B', 'B']
C ['C', 'C']
A ['A', 'A', 'A']
实际上挑选规则是通过函数完成的,只要作用于函数的两个元素返回的值相等,这两个元素就被认为是在一组的,而函数返回值作为组的key。如果我们要忽略大小写分组,就可以让元素’A’和’a’都返回相同的key:1
2
3
4
5
6
7>>> for key, group in itertools.groupby('AaaBBbcCAAa', lambda c: c.upper()):
... print key, list(group)
...
A 'A', 'a', 'a'
B 'B', 'B', 'b'
C 'c', 'C'
A 'A', 'A', 'a'
生成器表达式(Generator expression)和列表解析(List Comprehension)
1. (x+1 for x in lst) #生成器表达式,返回迭代器。外部的括号可在用于参数时省略。
2. [x+1 for x in lst] #列表解析,返回list
由于返回迭代器时,并不是在一开始就计算所有的元素,这样能得到更多的灵活性并且可以避开很多不必要的计算,所以除非你明确希望返回列表,否则应该始终使用生成器表达式。
为列表解析提供if子句进行筛选:1
(x+1 for x in lst if x!= 0)
或者提供多条for子句进行嵌套循环,嵌套次序就是for子句的顺序:1
((x,y) for x in range(3) for y in range(x))
应用场景
1. 当对元素应用的动作太复杂,不能用一个表达式写出来时?
将动作def封装成函数,用于解析式;
2. 因为if子句里的条件需要计算,同时结果也需要进行同样的计算,不希望计算两遍?
组合一下列表解析式: [x for x in (y+1 for y in lst) if x >0],内部的列表解析变量其实也可以用x,但为清晰起见我们改成了y。
写在最后
推荐一个画分满满萌萌哒的关于Iterators , Iterables and Generators 的文章: How to train your Python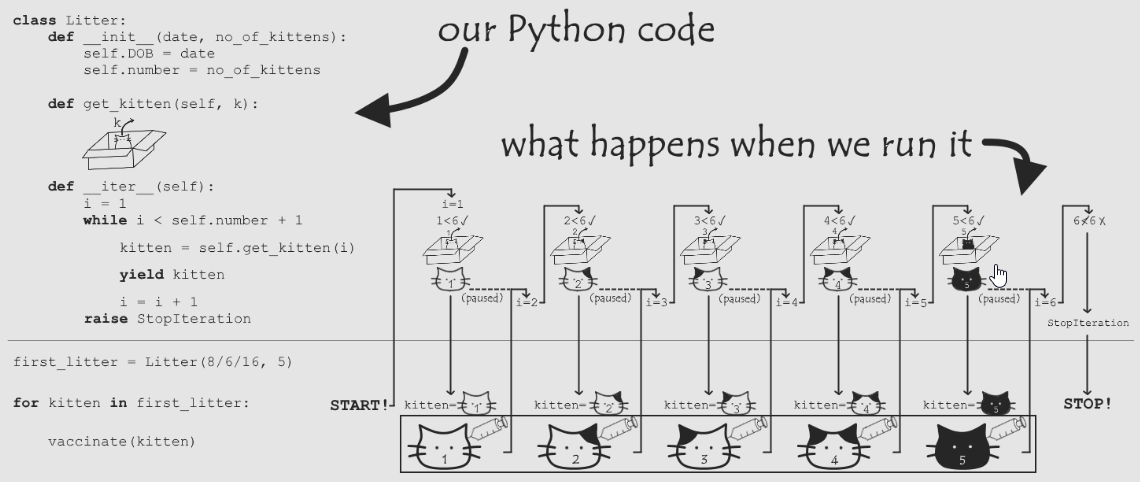
参考来源:
